
這篇我們會從使用者下了 SQL 指令開始、路途中經過連線池 (connection pool)、解析器 (parser)、優化器 (optimizer)… 等的過程紀錄下,希望這篇文章有幫助到你 🙂
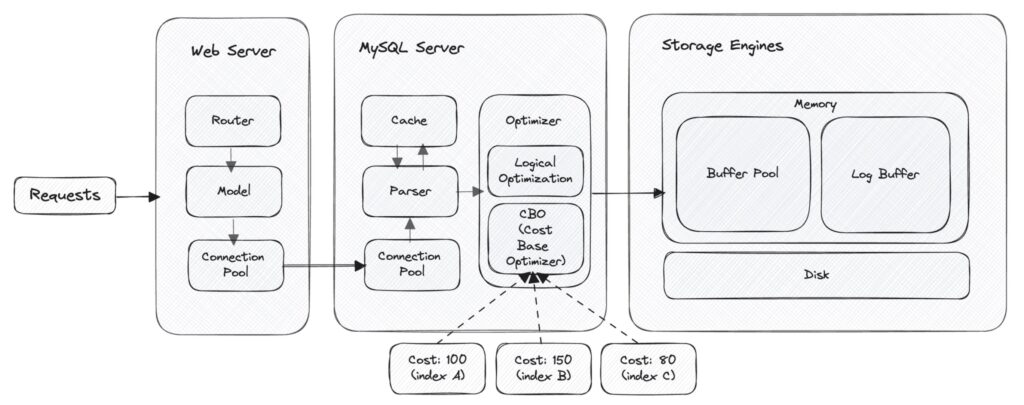
Table
Phase 1 – Connection Pool (連線池)
1-1. 什麼是 Connection Pool?
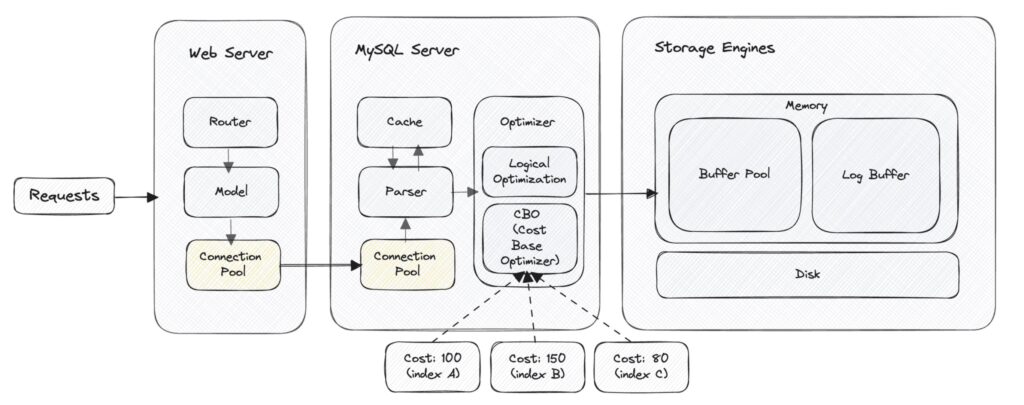
如果把 Connection Pool 想像成一間公司,那公司的 HR 部門就像是連線池,負責招募員工 (資料庫連線) 來處理處理大量的任務。
- 招募員工數 (pool_size):
pool_size=10,HR 先預估的業務需求,決定先招募 10 名員工準備在公司中工作。 - 員工最長工時 (pool_recycle):
pool_recycle=3600,代表 HR 部門每隔一小時 (3600秒) 會檢查一次員工的工作狀況,如果發現有員工 (資料庫連線) 已經工作了很長時間,為了避免潛在的過勞問題或是連接過時,HR 會決定讓這名員工休息。 - 等待時間 (pool_timeout) :
pool_timeout=30,表示當所有員工都在忙碌時,如果有新的任務 (資料庫請求) 到來,公司會讓這個任務等待最多 30 秒。如果 30 秒後仍然沒有員工空閒,則會返回錯誤,告知目前員工太忙無法接受新任務。 - 根據業務量調整人手 (max_overflow):
max_overflow=5,表示在正常工作人數 (pool_size)之上,如果突然來了很多任務,HR 部門可以臨時招募最多 5 名員工來處理額外的工作量。
透過這種方式,公司 (應用程式) 可以更高效地處理任務 (資料庫操作),同時保持對人力資源 (資料庫連線) 的有效管理,避免資源浪費。
1-2. Web Server (FastAPI) 的 Connection Pool
|
1 2 3 4 5 6 7 8 9 10 |
from sqlalchemy import create_engine engine = create_engine( "postgresql://user:password@localhost/dbname", pool_size=10, max_overflow=10, pool_timeout=30, pool_recycle=1800 ) |
以下的設定就像我們剛剛的 HR,設定了總員工數、工時、等待時間和額外招募人數:
- pool_size=10:連線池的大小 (總員工數)
- max_overflow=10:指定在連線池達到 pool_size 後可以創建的最大連線數,如果設定 -1 則可以無限大 (額外招募)
- pool_timeout=30:是當所有連線都在使用時,新請求等待獲得可用連線的最長時間(秒)(客戶等待時間)
- pool_recycle=1800:超過這個時間連線就會被關閉並重新建立,以避免資料庫連線過時 (員工最長工時)
1-3. DB Server (MySQL) 的 Connection Pool
|
1 2 3 4 |
SHOW VARIABLES LIKE 'max_connections'; # 數據庫同時允許的最大連接數量 SHOW VARIABLES LIKE 'wait_timeout'; # 可以保持閒置狀態的時間 SHOW VARIABLES # 查看更多其他參數 ... |
MySQL 的 server 也可以設定類似的參數,想了解更多可以從 SHOW VARIABLES 來查看
Phase 2 – Parser (解析器)
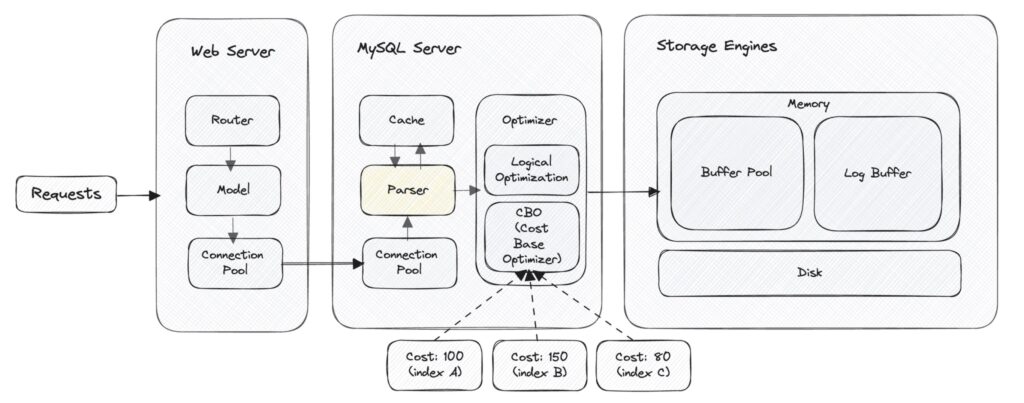
2-1. 什麼是 Parser?
Parser (解析器) 最主要功能是進行「語法檢查」,和將人類的查詢文字轉換為機器可以理解結構化形式的「 (AST 抽象與法樹)」, 供後續階段 Optimizer (優化器) 處理。
這個過程可以細分為以下幾個主要階段:
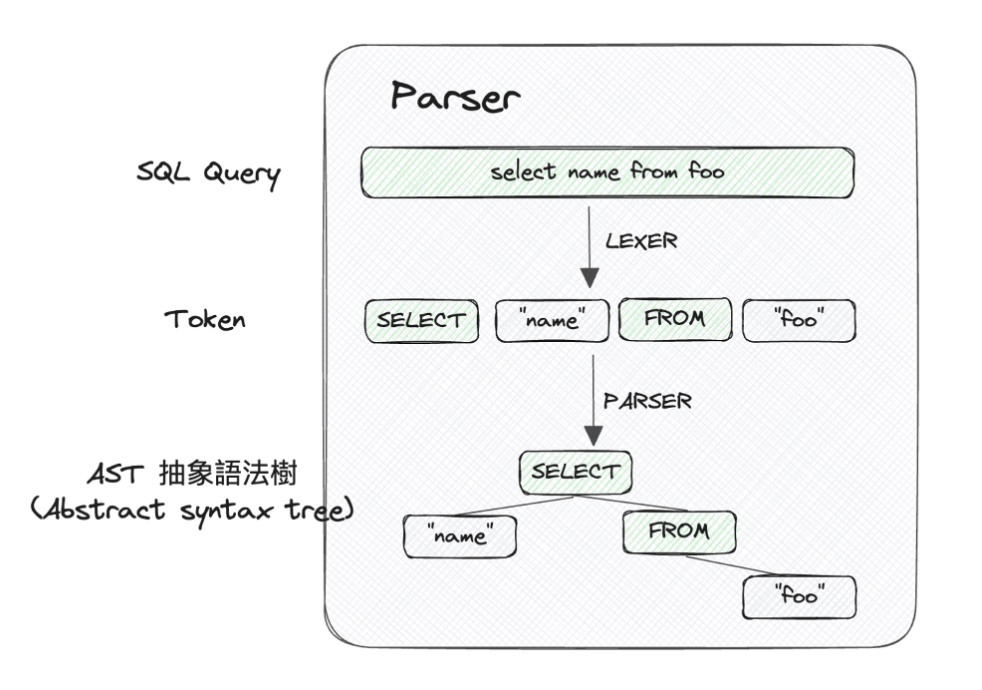
2-1-1. 詞法分析 (Lexical Analysis)
- 將 SQL 查詢分解成一系列基本的單元或符號,稱為標記(tokens)。這些標記包括關鍵字、常量、操作符等。
- 例如把 “SELECT name FROM foo” 分解成 “SELECT”, “name”, “FROM”, “foo” 等標記。
2-1-2. 語法分析 (Syntax Analysis)
- 檢查這些標記是否按照 SQL 的語法規則正確組合,在這個階段,會生成一個抽象語法樹(AST),是一種表達語法結構和標記關係的樹狀結構。
- AST 清晰地反映了查詢的結構,每一個節點代表查詢中的一種結構 (例如表達式、操作符等)。高度結構化的表示,使得後續步驟可以更加有效地進行。
Parser 延伸閱讀
- Grammatically Rooting Oneself With Parse Trees
- Leveling Up One’s Parsing Game With ASTs
- Let’s Build A Simple Interpreter. Part 7: Abstract Syntax Trees
Phase 3 – Optimizer (優化器)
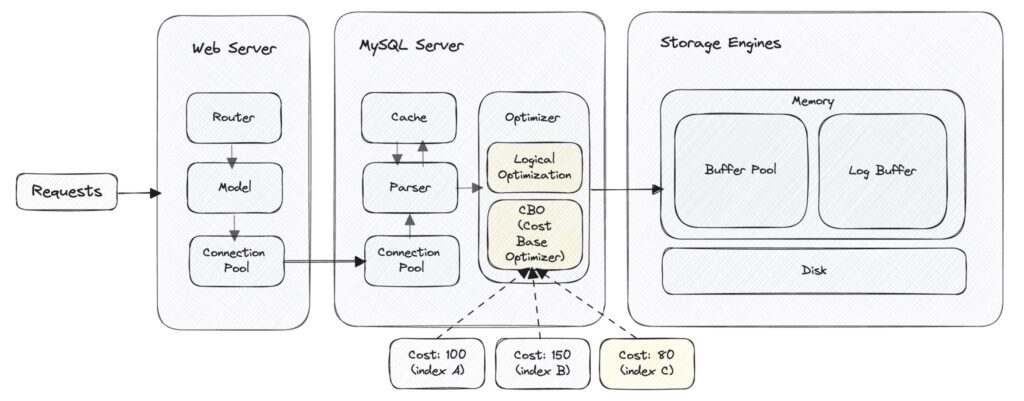
在 Optimizer 優化器的過程中,主要會分成兩個階段,分別是邏輯優化和基於成本優化:
3-1. 邏輯優化 (Logical Optimization)
這一階段的目的是在「不改變查詢結果」的前提下,重新構造查詢,例如:刪除無用的邏輯,像是底下是一個簡單的 SQL 查詢:
|
1 2 |
SELECT name FROM `tableA` WHERE 1 = 1; |
但如果我們使用 EXPLAIN 來看,可以看到優化器自動刪除了 1 = 1 的部分:
|
1 2 3 |
EXPLAIN SELECT name FROM `tableA` WHERE 1 = 1; >>> Note: #1003 /* select#1 */ select `name` from `tableA` |
3-2. 基於成本優化器 (CBO, Cost-Based Optimizer)
這邊的 Cost 代表了 Server Cost + Engine Cost,也就是 CPU Cost + IO Cost,使用不同的 index 來查表的話,會有不同的 Cost,而 CBO 是取成本最少的來進行查詢。
成本的部分,可以從 engine_cost 和 engine_cost 兩張表查詢成本:
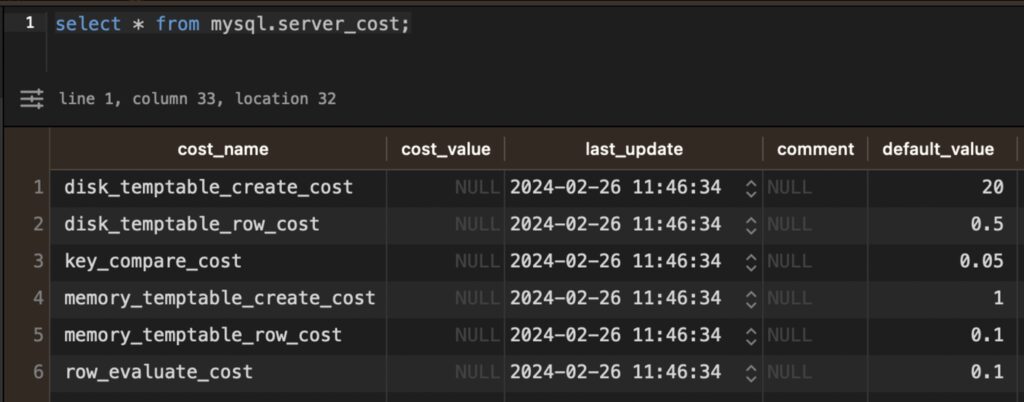
3-2-1. Server Cost (CPU Cost)
(select * from mysql.servert_cost;)
3-2-2. Engine Cost (IO Cost)
(select * from mysql.engine_cost;)
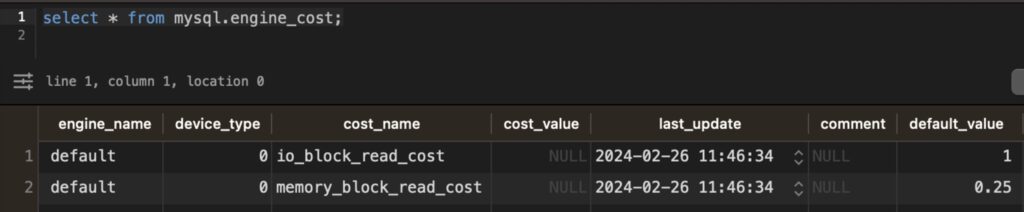
(可以看到從硬碟是記憶體讀取成本的 4 倍)
3-2-3. 簡單範例
我們今天針對 table_A 做 query (explain format=json select * from table_A;)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
{ "query_block": { "select_id": 1, "cost_info": { "query_cost": "0.65" }, "table": { "table_name": "table_A", "access_type": "ALL", "rows_examined_per_scan": 4, "rows_produced_per_join": 4, "filtered": "100.00", "cost_info": { "read_cost": "0.25", "eval_cost": "0.40", "prefix_cost": "0.65", "data_read_per_join": "8K" }, "used_columns": [ "created_by", "created_at", "updated_by", "updated_at", "id", "project_id", "project_kpi" ] } } } |
可以看到 query_cost = 0.65,這 cost 是從 Server Cost + Engine Cost 所獲得
- Engine Cost (IO Cost):
- 16384 / 16 / 1024 = 1 (每頁預設 16KB,然後 1KB = 1024 字節,得到讀取多少頁)
- 1 * 0.25 (memory_block_read_cost) = 0.25
- Server Cost (CPU Cost):
- 4 * 0.1 (row_evaluate_cost) = 0.4
*補充:16384 是 Data_length,4 是 Rows,可以從這邊取的 show table status like 'table_A';
|
1 2 |
Data_length: 16384 Rows: 4 |
0.25 + 0.4 = 0.65,也就是我們這次的 query_cost,以上就是一個簡單的 CBO 成本計算的過程。
CBO 延伸閱讀
那本篇「SQL Query 的一天過得好嗎 (上)」就在這邊告一個段落,我們經歷了 SQL 的連線池 (connection pool)、解析器 (parser)、優化器 (optimizer),在下集我們會繼續 SQL 的下半,感謝收看 🙂
延伸閱讀
▍資料庫相關:
▍其他相關教學目錄: